
天基综合信息系统全国重点实验室入选ICML 2026论文概览
文章来源: | 发布时间:2026-07-03 | 【打印】 【关闭】
近日,软件所天基综合信息系统全国重点实验室多篇论文被机器学习领域国际学术会议International Conference on Machine Learning 2026 (ICML 2026)录用。以下是成果介绍,欢迎大家交流讨论。
1. OrchJail: Jailbreaking Tool-Calling Text-to-Image Agents by Orchestration-Guided Fuzzing
作者:陈建明、王亚文、王俊杰、刘哲、王青、徐帆江
当前,文生图系统正从单次生成转向“生成+多轮编辑”的智能体模式,由规划器调用多种工具完成复杂任务。但多步工具链的组合可能逐步逼近违规目标,传统仅依赖提示词文本逃逸的越狱方法难以应对这一新挑战,主要面临两个问题:一是难以建模提示词如何引导规划器生成特定工具链,无法捕获链路级风险;二是攻击者无法获知内部规划逻辑,搜索过程容易陷入盲目试错,效率低下。
为此,团队提出一种编排引导的模糊测试方法OrchJail。该方法包含两个关键设计:一是编排抽象,将越狱成功轨迹中的工具调用日志压缩为结构化编排模式,识别高风险工具序列;二是编排知识驱动的模糊搜索,通过工具感知生成初始种子,并借助历史案例库与多目标打分机制,提升搜索效率。
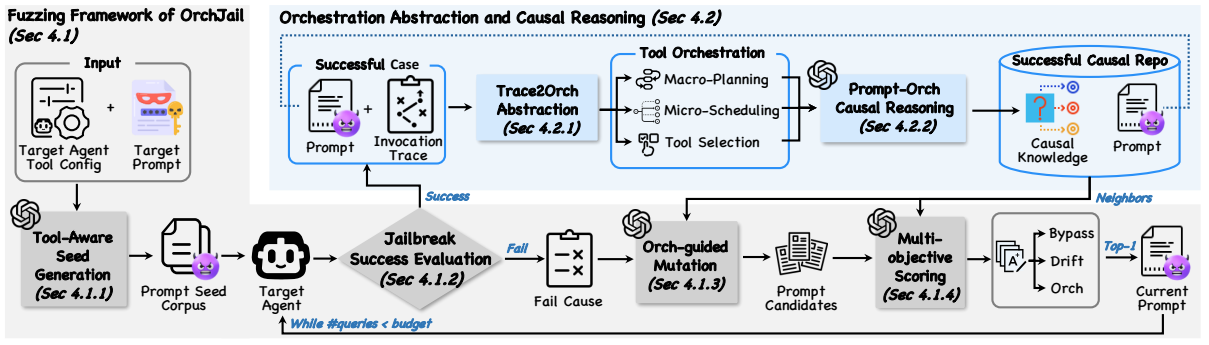
OrchJail框架图
研究团队在三个具有代表性的文生图智能体上进行了系统对比实验。结果显示,OrchJail在越狱成功率、图像质量与查询效率等指标上均优于多种主流基线方法。
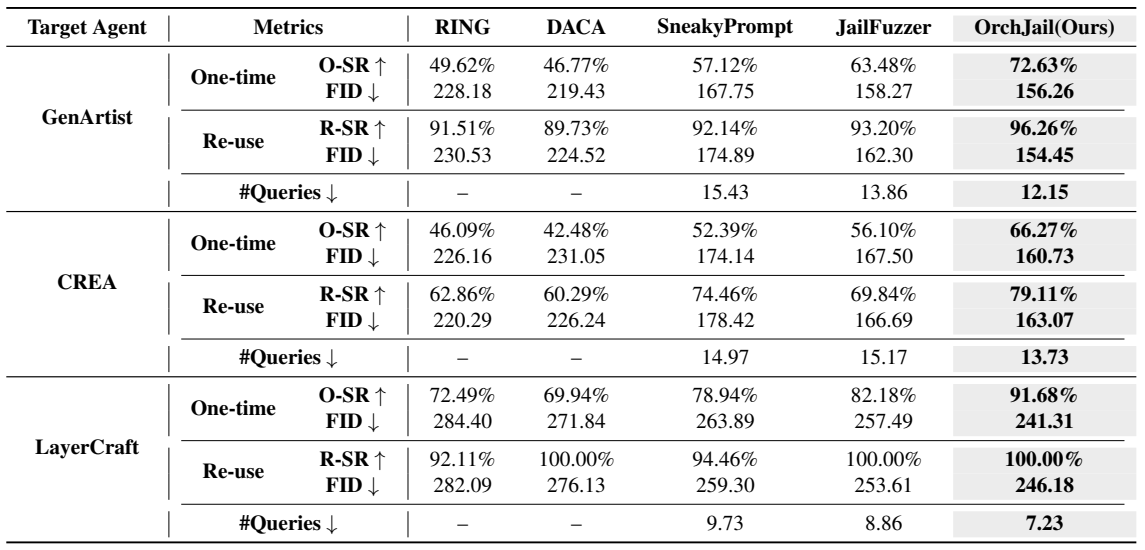
对比实验结果
论文链接:https://arxiv.org/abs/2605.07414v1
2. On the Plasticity and Stability for Post-Training Large Language Models
作者:强文文、顾子茵、周嘉欢、胡杰、王婧瑶、郑昌文、熊辉
大语言模型(LLMs)已经证明强化学习对于解锁复杂的推理能力至关重要。当前主流强化学习方法GRPO虽内存占用低、易于扩展,但训练中常面临两难:为提升推理能力(可塑性)进行激进更新,容易导致通用知识遗忘;为保持稳定性施加严格约束,又可能阻碍推理能力提升。
研究团队分析认为,推理与稳定性两个优化目标的梯度方向常相互冲突,而标准GRPO直接相加两向量,造成优化效率低下。更复杂的是,这些梯度基于少量样本估计,本身存在噪声,传统“硬投影”方法难以直接适用。因此,团队提出概率冲突解决机制(Probabilistic Conflict Resolution,PCR)。该机制不再将梯度视为固定方向,而是建模为随机变量以量化其不确定性,并通过贝叶斯推理动态仲裁冲突:信号强且精确时允许更新,噪声大则抑制更新,形成“软投影”。同时,为兼顾计算效率,PCR仅应用于承载核心知识的MLP层,注意力层保持标准更新。

动机实验结果图
实验表明,PCR在多个推理基准上稳定优于多个强基线方法,且训练过程梯度更新更平滑,避免剧烈震荡。
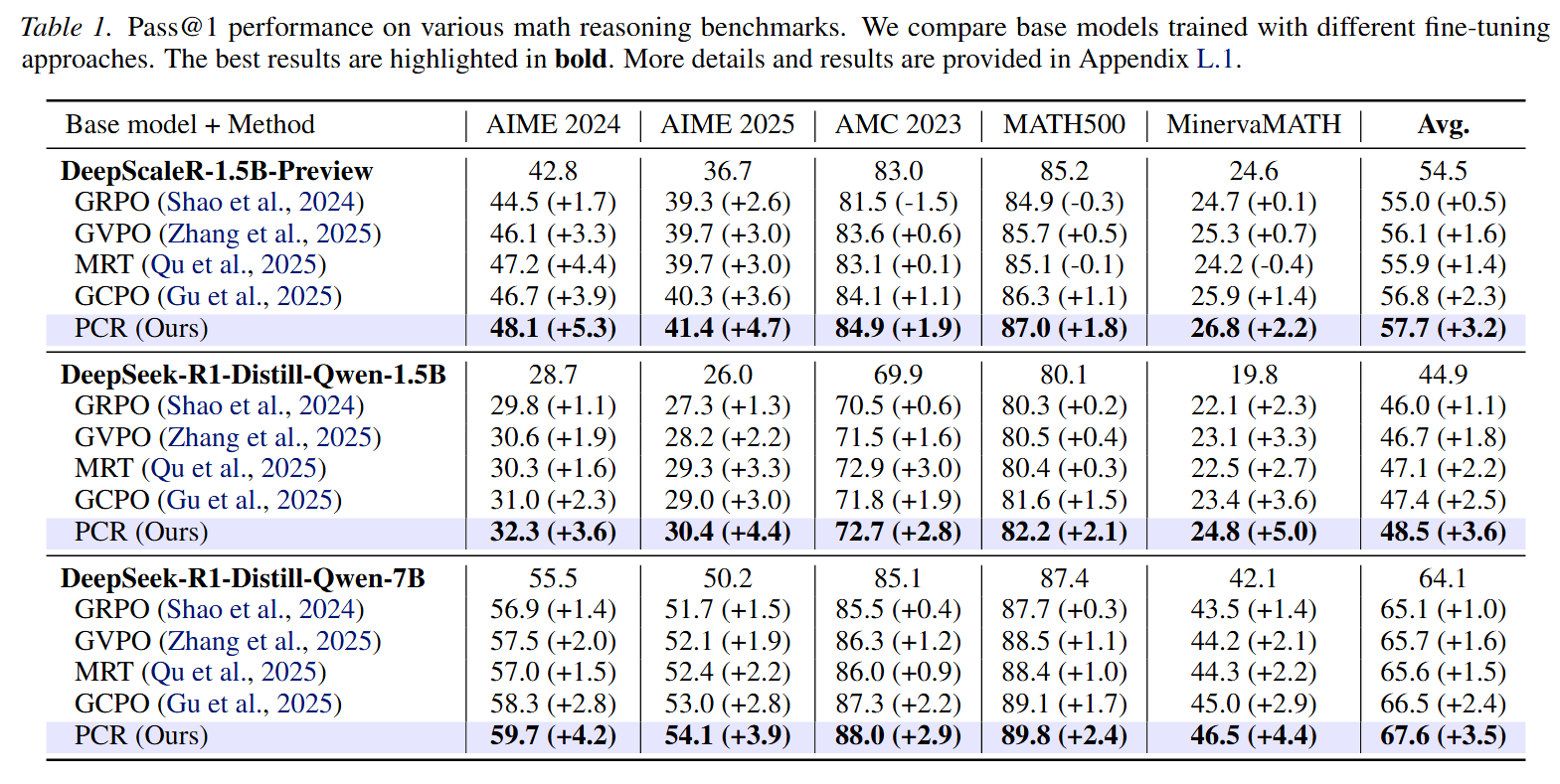
实验结果
论文链接:https://arxiv.org/abs/2602.06453
3. Efficient Code Analysis via Graph Representation Learning-Guided Large Language Models
作者:高航、彭涛、崔保全、黄鸿、吴凤鸽、赵军锁、张健
大语言模型虽擅代码理解,但在处理跨文件、依赖复杂的Python项目时存在局限:恶意逻辑常分散在多处并通过调用链串联,序列化模型难以捕捉,且面对长代码输入时算力开销大;传统检测工具往往泛化性弱、可解释性不足,现有技术难以满足开源代码大规模筛查的实际需求。
为此,研究团队设计了由图神经网络与大语言模型协同工作的双阶段检测框架GMLLM。该框架首先将项目整体构建为代码图(类、函数、模块为节点,依赖与调用为边),利用大模型生成敏感行为规则,再经图卷积网络训练进行初步风险判定。在此基础上,团队引入掩码解释技术,筛选出对恶意判定贡献最大的高风险子图,将其精简后输入大模型,完成最终判定、攻击路径梳理与安全建议输出,兼顾精度与效率。
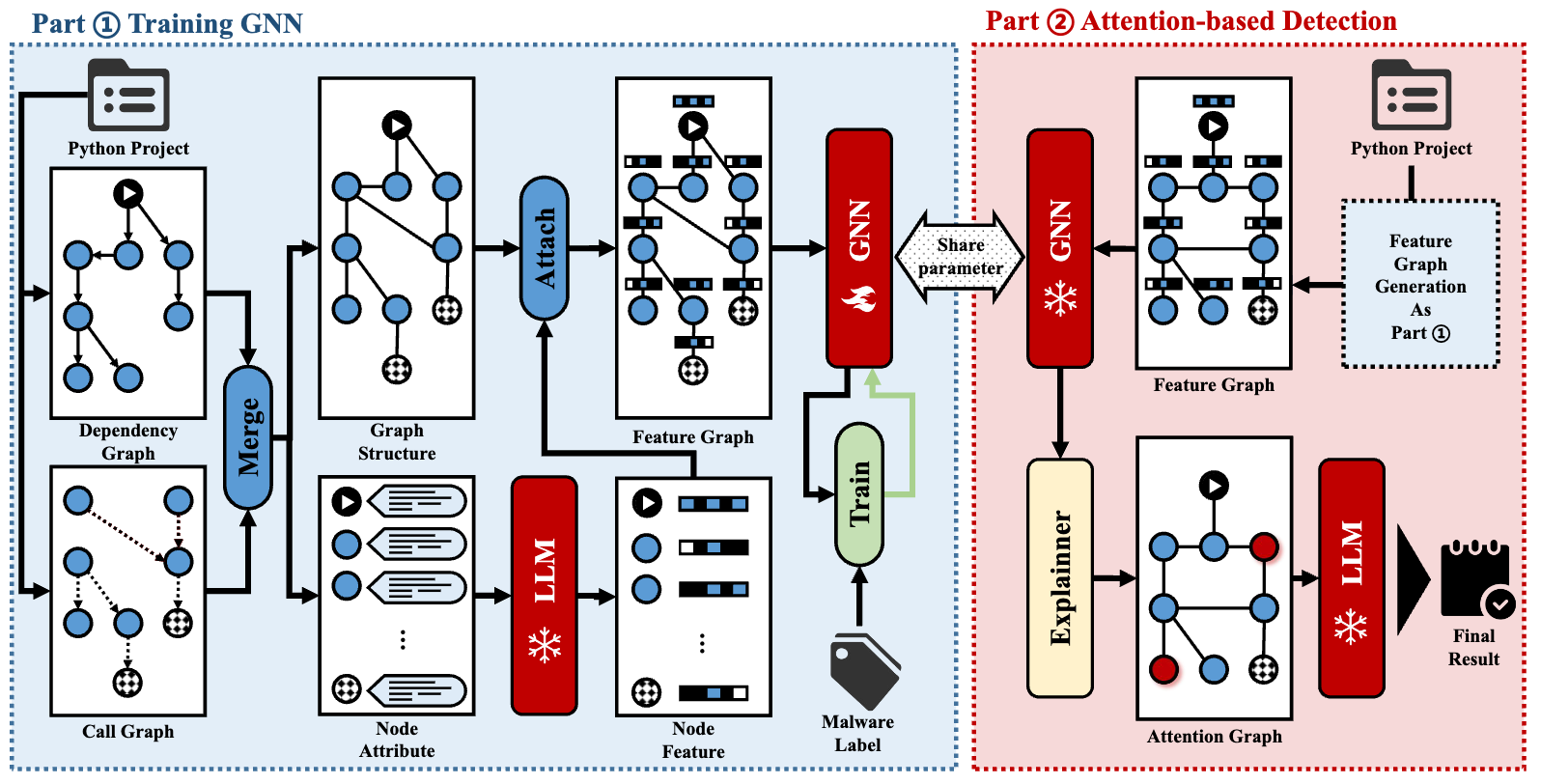
GMLLM框架图
为验证所提方法的有效性,研究团队在Backstabbers、Datadog、Mal-OSS等公开数据集,以及自研大规模Python恶意代码数据集MalCP开展全面实验。结果表明,GMLLM在评估数据集上取得优于现有基准的性能,验证了其方法的合理性与实际有效性。
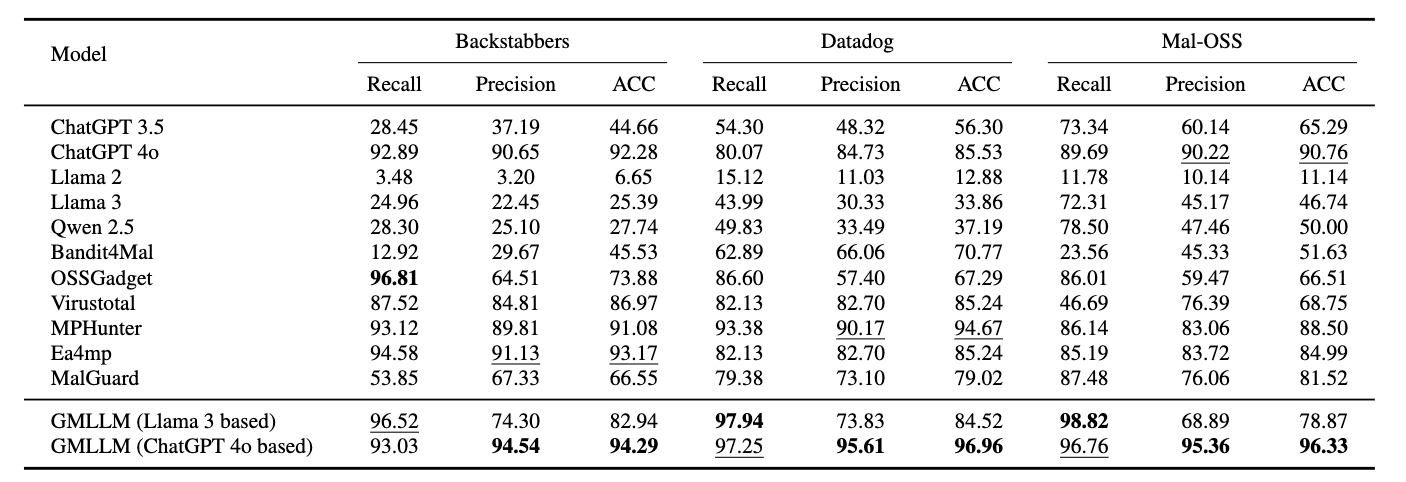
GMLLM在数据集上的实验结果




