软件所提出自监督学习泛化能力提升新方法
软件所天基综合信息系统全国重点实验室的研究团队在自监督学习领域取得进展。研究论文《自监督学习中的泛化能力与因果解释》(On the Generalization and Causal Explanation in Self-Supervised Learning),被人工智能领域的权威期刊《国际计算机视觉杂志》(International Journal of Computer Vision)收录。该论文的共同第一作者为特别研究助理强文文和博士生宋泽恩,通讯作者为特别研究助理李江梦。
论文深入探讨了自监督学习(SSL)在训练过程中可能遇到的过拟合问题,并提出了一种创新的双层优化方法——撤销记忆机制(Undoing Memorization Mechanism,简称UMM),以增强模型的泛化能力。自监督学习是一种利用未标记数据进行学习的方法,它在多种下游任务中展现出了卓越的泛化能力。然而,这种学习方法存在训练数据过拟合的风险,可能会削弱模型适应新任务的能力。
研究团队通过实验发现,随着自监督学习训练轮次的增加,基于深度神经网络最后层学习的特征在验证集上的准确率会先提升至一个峰值,然后持续下降并最终趋于稳定。相比之下,基于中间层学习的特征展现出了更强的泛化能力,其在验证集上的准确率在达到峰值后几乎保持不变。此外,他们还发现编码降低率(CRR)与验证集准确率的变化趋势高度一致。使用CRR来量化过拟合现象,相较于使用验证集准确率,具有无需标签信息、计算量小且耗时短的优势。
基于上述发现,研究团队提出了UMM算法。该算法采用双层优化机制,首先通过Jensen-Shannon散度使最后层的特征分布尽量与中间层的特征分布对齐。然后,利用中间层特征的分布信息,约束最后层特征的编码降低率,使其在达到最高值后保持稳定,不再下降,从而减轻自监督学习训练过程中的过拟合现象,并恢复最后层的泛化能力。
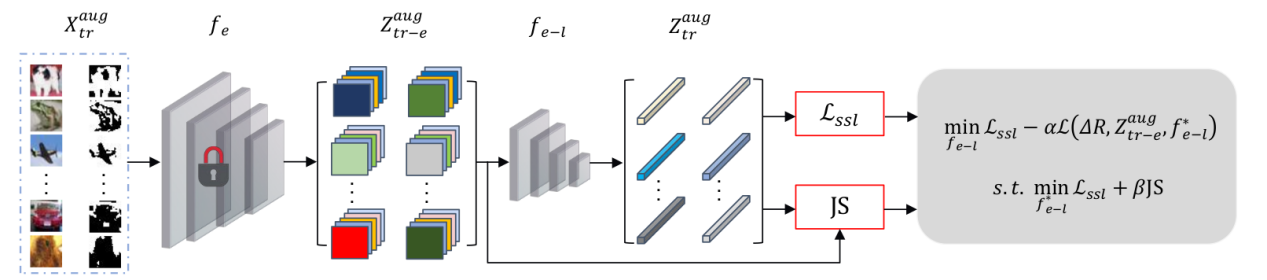
撤销记忆机制(UMM)框架图
进一步的理论分析表明,随着自监督学习轮次的增加,最后层学习特征基于记忆效应会包含大量任务无关因子的信息量,这会导致任务相关因子信息量减少,进而削弱泛化能力。UMM的引入可以增加最后层学习特征中与任务相关的信息量,从而提升模型的泛化能力。
研究团队还在分类、检测、实例分割等多种下游任务上进行了广泛的实验。实验结果表明,引入UMM后,在多个基线上实现了稳定的性能提升,进一步验证了UMM算法的有效性。这一成果为自监督学习领域提供了新的视角和解决方案,有望推动相关技术的发展和应用。
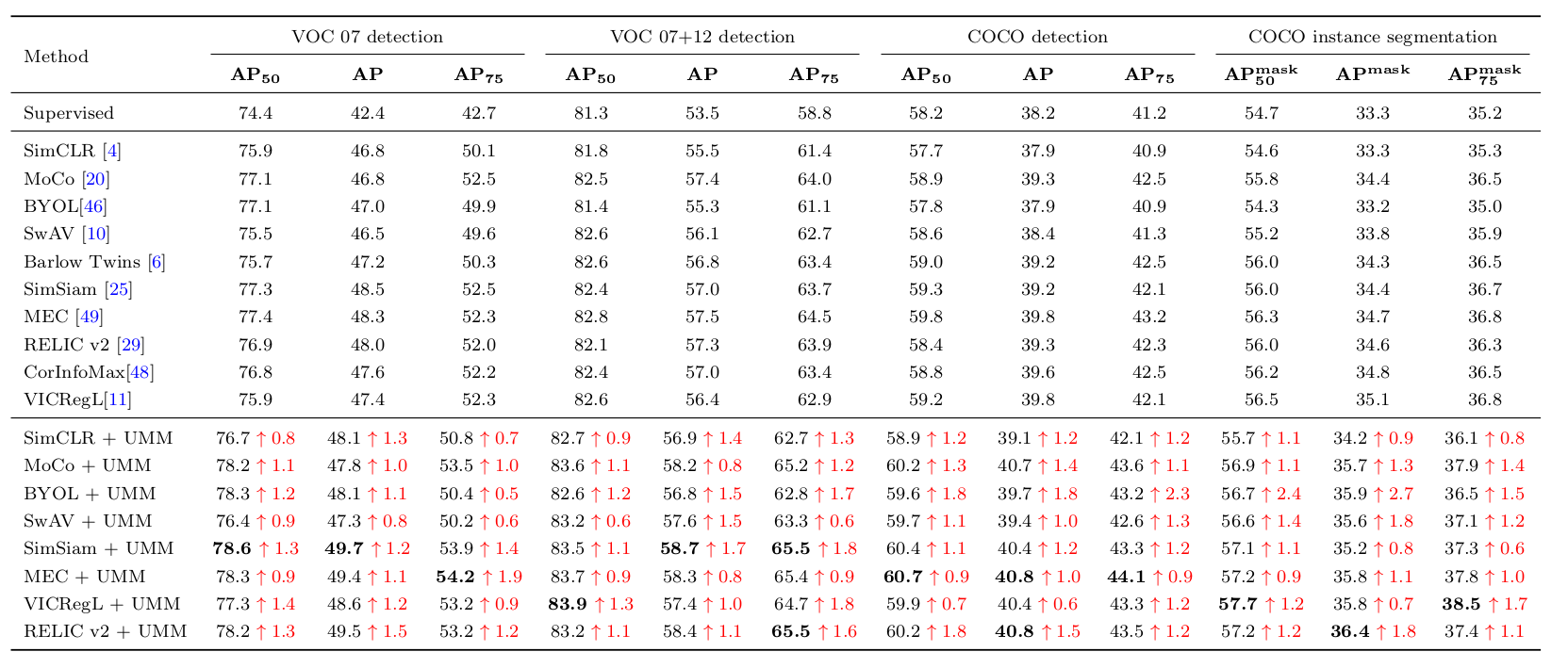
UMM在目标检测和实例分割任务上的实验结果
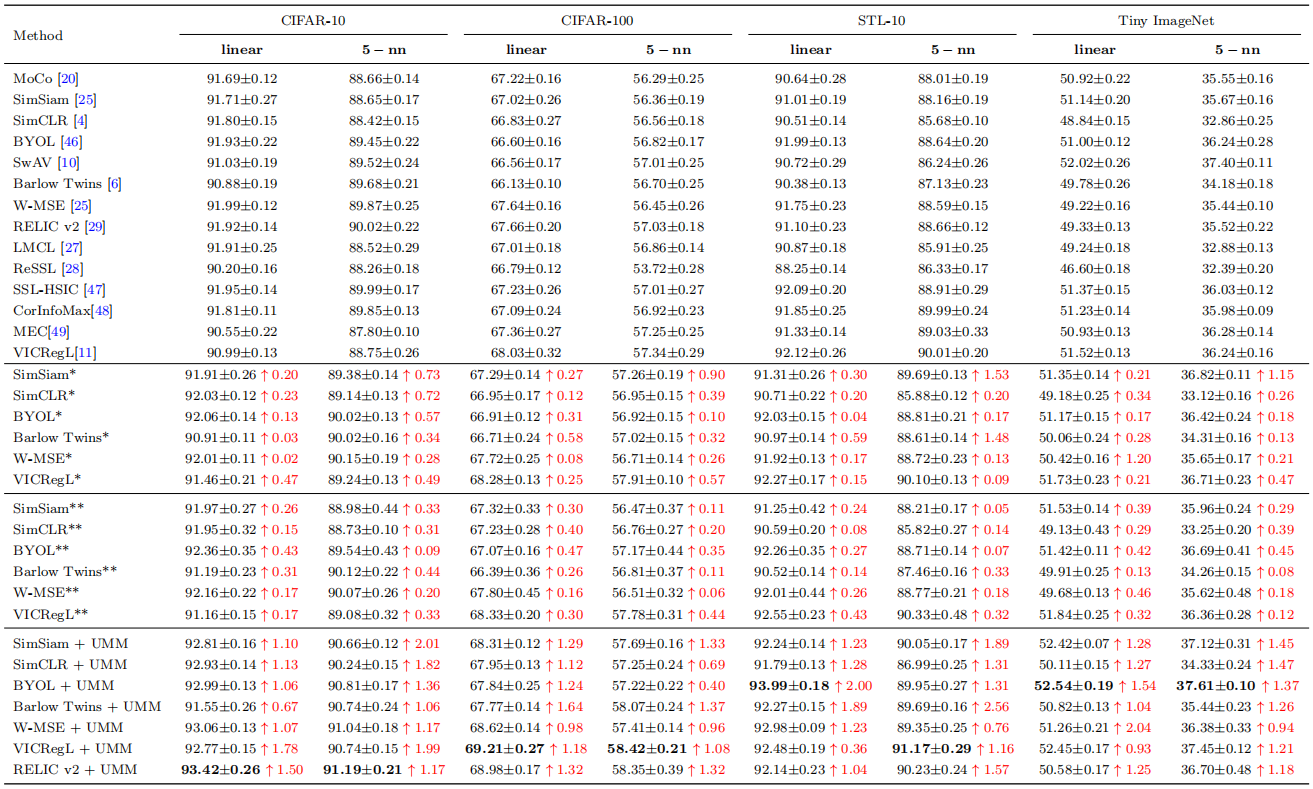
UMM在无监督学习任务上的实验结果